目录
基于版本:MongoDB 6.0
简介
数据库简介
数据库是按照数据结构来组织、存储和管理数据的仓库
- 关系型数据库(RDBMS)
- MySQL、Oracle、DB2、SQL Server
- 关系数据库中全都是表
- 非关系型数据库(No SQL)
- MongoDB、Redis
- 键值对数据库
- 文档数据库:MongoDB
MongoDB简介
MongoDB是为快速开发互联网Web应用而设计的数据库系统
MongoDB的设计目标是极简、灵活、作为Web应用栈的一部分
MongoDB的数据模型是面向文档的,所谓文档是一种类似于JSON的结构(BSON)
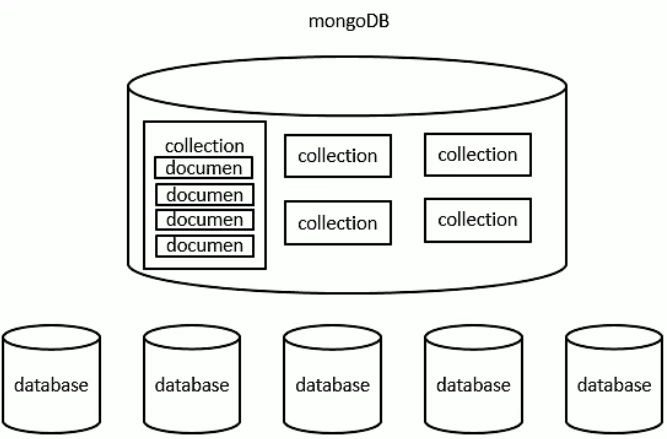
三个概念:
- 数据库
database - 集合
collection - 文档
document:最小单位 - 在MongoDB中,数据库和集合都不需要手动创建,当创建文档时,如果文档所在的数据库或集合不存在则会自动创建
安装与配置
Windows下安装
下载地址,安装server和shell
下载msi安装版或zip解压版,安装完成后进入安装目录,将bin目录添加到环境变量,安装目录(与bin同级)若没有data和log目录,则需要手动创建,在log目录下创建mongod.log文件。
打开两个窗口,输入mongod启动服务,输入mongosh连接到MongoDB,在浏览器地址栏输入localhost:27017,出现It looks like you are trying to access MongoDB over HTTP on the native driver port.即为配置成功。
启动命令:mongod --dbpath 数据库路径 --port 端口号
将MongoDB设置为系统服务,可以自动在后台启动(新版本已经默认写入系统服务)
CentOS 7下安装
译者2024注
后来个人觉得还是docker香
默认使用root用户,如果使用非root用户登录请手动添加sudo
-
安装Server
访问 MongoDB Community Downloads | MongoDB ,下载适合自己系统的rpm文件,本文使用CentOS 7.2,因此寻找
RedHat / CentOS 7.0 x64,下载Server Package和Mongos Package,可以使用wget命令进行下载,也可先下载到本地后再通过sftp上传执行安装:
shellrpm -ivh mongodb-org-mongos-6.0.2-1.el7.x86_64.rpm rpm -ivh mongodb-org-server-6.0.2-1.el7.x86_64.rpm配置访问权限:
shellchown -R mongod:mongod /var/lib/mongo # 数据存储目录 chown -R mongod:mongod /var/log/mongodb # 日志目录 chown mongod:mongod /tmp/*.sock # 代码中的*为通配符,表示合法文件名
如图所示即为安装成功
-
安装mongosh
访问MongoDB Shell Download | MongoDB,选择适合自己系统的文件,这里选择
Linux Tarball 64-bit,下载tgz压缩包,可以使用wget命令进行下载,也可先下载到本地后再通过sftp上传执行解压
shelltar -zxvf mongosh-1.6.1-linux-x64.tgzcd到解压后的文件夹中,分别执行如下命令:
shellchmod +x bin/mongosh cd bin cp mongosh /usr/local/bin cp mongosh_crypt_v1.so /usr/local/bin -
设置防火墙
如果正在运行防火墙(firewalld),则还需要打开27017端口:
shellfirewall-cmd --permanent --zone=public --add-port=27017/tcp firewall-cmd --reload云服务器也可以在控制台的防火墙页面配置入流量
-
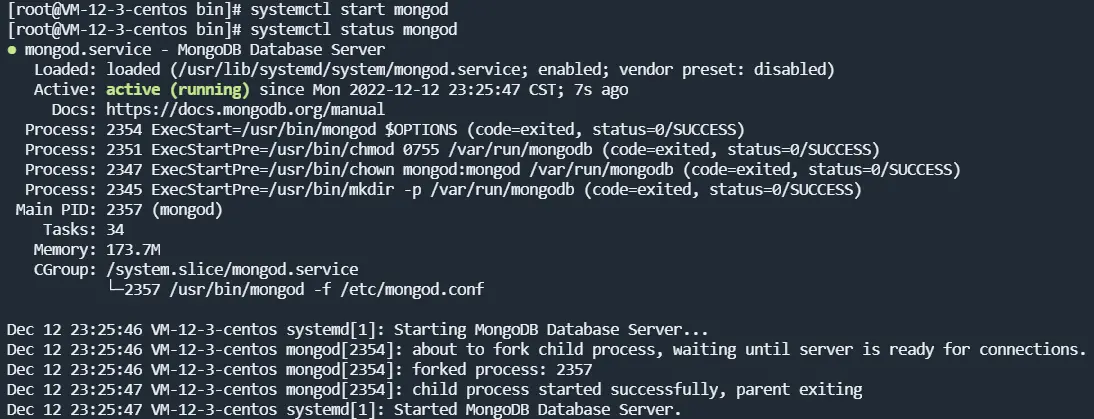
启动服务
启动:
systemctl start mongod停止:
systemctl stop mongod开机自启:
systemctl enable mongod查看服务状态:
systemctl mongod启动服务成功如下所示:
在浏览器地址栏输入
<ip>:27017,出现It looks like you are trying to access MongoDB over HTTP on the native driver port.即为配置成功 -
使用mongosh
终端输入
mongosh即可连接到Mongo Server -
配置管理员账号
使用mongosh连接到mongodb,切换到admin数据库并创建管理员账号
sql# 切换到admin数据库 use admin # 创建管理员账号 db.createUser({user: "root", pwd: "123456", roles: ["root"]})vim /etc/mongod.conf修改配置,修改security内容如下:#增加开启权限配置 security: authorization: enabled重启服务:
systemctl restart mongod -
可能出现的问题
Job for mongod.service failed because the control process exited with error code.systemctl status mongod查看错误代码为14: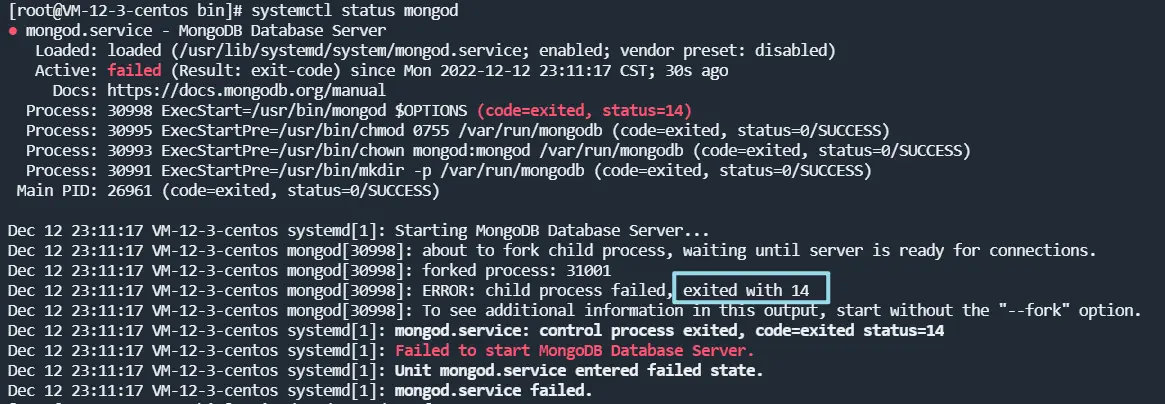
用户mongod没有对必需文件的写权限,导致数据库服务不能启动,按照步骤1中配置权限即可
图形化工具安装
- Studio 3T
- NoSQL Manager
- Navicat
- DataGrip
基本使用
基本指令
-
show dbs或show databases显示数据库

-
use 数据库名进入数据库
-
db查看当前所在数据库
-
show collections显示数据库中所有的集合

-
db.<collection>.insertOne(doc)向当前数据库的集合中插入一个文档
-
db.<collection>.find()查看集合中所有文档
查询和投影运算符
查询运算符
比较运算符
| Name | Description |
|---|---|
$eq | 等于 |
$gt | 大于 |
$gte | 大于等于 |
$in | 包含在数组中 |
$lt | 小于 |
$lte | 小于等于 |
$ne | 不等于 |
$nin | 不包含在数组中 |
逻辑运算符
| Name | Description |
|---|---|
$and | 且:同时符合条件 |
$not | 非:与查询表达式不匹配 |
$nor | 或非:与条件都不匹配 |
$or | 或:满足任一条件 |
要素运算符
| Name | Description |
|---|---|
$exists | 匹配存在指定字段的文档 |
$type | 选择字段是指定类型的文档 |
评估运算符
| Name | Description |
|---|---|
$expr | 允许在查询语言中使用聚合表达式 |
$jsonSchema | 根据给定的JSON模式验证文档 |
$mod | 对字段的值进行模运算,并选择具有指定结果的文档 |
$regex | 选择值与指定正则表达式匹配的文档 |
$text | 执行文本搜索 |
$where | 匹配满足JavaScript表达式的文档 |
空间运算符
| Name | Description |
|---|---|
$geoIntersects | 选择与 GeoJSON 几何形状相交的几何形状。该 2dsphere 索引支持 $geoIntersects。 |
$geoWithin | 选择边界 GeoJSON 几何内的 geometry。 该 2dsphere 和 2d 索引支持 $geoWithin。 |
$near | 返回点附近的地理空间对象。需要地理空间索引。 该 2dsphere 和 2d 索引支持 $near。 |
$nearSphere | 返回球体上某个点附近的地理空间对象。需要地理空间索引。该 2dsphere 和 2d 索引支持 $nearSphere。 |
数组运算符
| Name | Description |
|---|---|
$all | 匹配包含查询中指定的所有元素的数组 |
$elemMatch | 如果数组字段中的元素符合所有指定的$elemMatch条件,则选择文档 |
$size | 选择数组字段为指定大小的文档 |
按位运算符
| Name | Description |
|---|---|
$bitsAllClear | 匹配数值或二进制值,其中一组位位置的 都 具有值0 |
$bitsAllSet | 匹配数值或二进制值,其中一组位位置的 都 具有值1 |
$bitsAnyClear | 匹配数字或二进制值,其中一组位位置中的 任何 位的值为0 |
$bitsAnySet | 匹配数字或二进制值,其中一组位位置中的 任何 位的值为1 |
投影运算符
| Name | Description |
|---|---|
$ | 投影数组中与查询条件匹配的第一个元素 |
$elemMatch | 投影数组中与指定 $elemMatch 条件匹配的第一个元素 |
$meta | 投影 $text 操作期间分配的文档分数 |
$slice | 限制从数组投影的元素数量,支持跳过和限制切片 |
混杂运算符
| Name | Description |
|---|---|
$comment | 向查询谓词添加注释 |
$rand | 生成0到1之间的随机浮点数 |
CRUD
插入文档
插入单个文档:db.<collection>.insertOne(doc),doc为json对象格式
插入多个文档:db.<collection>.insertMany(docArray),docArray为包含json对象的数组
查询文档
参考样例:
jsondb.inventory.insertMany( [
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "A" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
]);
基本查询
-
基本命令:
db.inventory.find()或db.<collection>.find({}),对应SQL的select * from inventorydb.inventory.findOne()返回第一条数据db.inventory.find().count()返回总数 -
按条件查询:
db.inventory.find({"status": "D"}),对应SQL的select * from inventory where status= "D" -
使用查询运算符
$in指定查询条件:db.inventory.find( { status: { $in: [ "A", "D" ] } } ),对应SQL的SELECT * FROM inventory WHERE status in ("A", "D"),意为查询status为A或D的所有文档Although you can express this query using the
$oroperator, use the$inoperator rather than the$oroperator when performing equality checks on the same field. -
指定
AND条件查询:db.inventory.find( { status: "A", qty: { $lt: 30 } } ),对应SQL的SELECT * FROM inventory WHERE status = "A" AND qty < 30,意为查询status为A且qty小于30的文档 -
指定
OR条件查询:db.inventory.find( { $or: [ { status: "A" }, { qty: { $lt: 30 } } ] } ),对应SQL的SELECT * FROM inventory WHERE status = "A" OR qty < 30,意为查询status为A或qty小于30的文档 -
同时指定
AND和OR条件:jsdb.inventory.find( { status: "A", $or: [ { qty: { $lt: 30 } }, { item: /^p/ } ] } )对应SQL的
SELECT * FROM inventory WHERE status = "A" AND ( qty < 30 OR item LIKE "p%"),意为查询status为A且qty小于30或item以p开头
查询嵌套/嵌入文档
-
嵌套文档查询:
db.inventory.find( { size: { h: 14, w: 21, uom: "cm" } } ),精确查询size字段 -
嵌套字段查询:
db.inventory.find( { "size.uom": "in" } ),查询size字段下uom字段值为“in”;db.inventory.find( { "size.h": { $lt: 15 }, "size.uom": "in", status: "D" } )查询size.h小于15,size.uom为in,status为D
查询数组
参考样例:
jsdb.inventory.insertMany([
{ item: "journal", qty: 25, tags: ["blank", "red"], dim_cm: [ 14, 21 ] },
{ item: "notebook", qty: 50, tags: ["red", "blank"], dim_cm: [ 14, 21 ] },
{ item: "paper", qty: 100, tags: ["red", "blank", "plain"], dim_cm: [ 14, 21 ] },
{ item: "planner", qty: 75, tags: ["blank", "red"], dim_cm: [ 22.85, 30 ] },
{ item: "postcard", qty: 45, tags: ["blue"], dim_cm: [ 10, 15.25 ] }
]);
-
数组精确查询(包括顺序):
db.inventory.find( { tags: ["red", "blank"] } ),精确数组匹配,包括数组内元素顺序 -
数组包含元素查询(不考虑顺序):
db.inventory.find( { tags: { $all: ["red", "blank"] } } ),使用$all运算符查询包含red和blank的数组 -
查询包含某一元素的数组:
db.inventory.find( { tags: "red" } ) -
指定条件查询:
db.inventory.find( { dim_cm: { $gt: 25 } } ),查询数组dim_cm至少包含一个值大于25的元素的所有文档 -
搭配查询运算符指定多个条件
db.inventory.find( { dim_cm: { $gt: 15, $lt: 20 } } )db.inventory.find( { dim_cm: { $elemMatch: { $gt: 22, $lt: 30 } } } )
-
按索引查询:
db.inventory.find( { "dim_cm.1": { $gt: 25 } } ),查询数组dim_cm中第二个元素大于25的所有文档(下标从0开始)When querying using dot notation, the field and nested field must be inside quotation marks.
使用点表示法查询时,字段和嵌套字段必须在引号内。
-
按数组长度查询:
db.inventory.find( { "tags": { $size: 3 } } )
查询嵌套文档中的数组
参考样例:
jsdb.inventory.insertMany( [
{ item: "journal", instock: [ { warehouse: "A", qty: 5 }, { warehouse: "C", qty: 15 } ] },
{ item: "notebook", instock: [ { warehouse: "C", qty: 5 } ] },
{ item: "paper", instock: [ { warehouse: "A", qty: 60 }, { warehouse: "B", qty: 15 } ] },
{ item: "planner", instock: [ { warehouse: "A", qty: 40 }, { warehouse: "B", qty: 5 } ] },
{ item: "postcard", instock: [ { warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 } ] }
]);
-
精确匹配(包括字段顺序):
db.inventory.find( { "instock": { warehouse: "A", qty: 5 } } )与db.inventory.find( { "instock": { qty: 5, warehouse: "A" } } )的查询条件不同(顺序不同,后者查不到现有数据) -
指定数组字段的查询条件:
-
全部查询(查询数组中所有元素):
db.inventory.find( { 'instock.qty': { $lte: 20 } } ),查询满足instock数组中任一元素的qty属性小于等于20的文档 -
索引查询(查询数组指定索引位置的元素):
db.inventory.find( { 'instock.0.qty': { $lte: 20 } } ),查询满足instock数组的第一个元素的qty属性小于等于20的文档When querying using dot notation, the field and index must be inside quotation marks.
当使用
.进行查询时,字段和索引必须被引号包裹。
-
-
指定多个查询条件:使用
$elemMatch或.-
单一文档:
db.inventory.find( { "instock": { $elemMatch: { qty: 5, warehouse: "A" } } } ),查询instock数组至少有一个嵌入文档的文档,其中qty等于5,warehouse等于A,qty和warehouse在同一个文档中查询db.inventory.find( { "instock": { $elemMatch: { qty: { $gt: 10, $lte: 20 } } } } ),查询instock数组中至少有一个嵌入文档包含大于10且小于或等于20的qty的文档,qty和warehouse在同一个文档中查询
-
满足标准的要素组合:
db.inventory.find( { "instock.qty": 5, "instock.warehouse": "A" } ),instock数组中至少同时存在一个包含qty等于5的嵌入文档和一个包含warehouse等于A的嵌入文档的文档,这两个文档可以不是同一个文档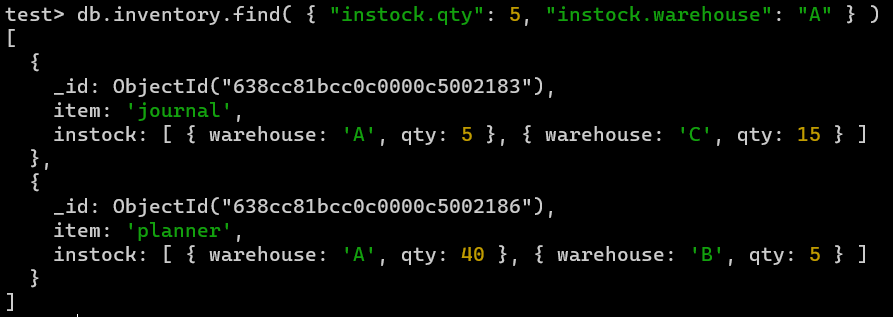
db.inventory.find( { "instock.qty": { $gt: 10, $lte: 20 } } ),instock数组中至少同时存在一个包含qty大于10的嵌入文档和一个qty小于等于20的嵌入文档的文档,这两个文档可以不是同一个文档
-
举例:
db.movies.find( { countries: "Mexico", "imdb.rating": { $gte: 7 } } ),从movies集合中查询国家为墨西哥且IMDB评分至少为7db.movies.find( { year: 2010, $or: [ { "awards.wins": { $gte: 5 } }, { genres: "Drama" } ] } ),使用$or运算符,从movies集合中查询2010年发行且获得至少五个奖项或类型为戏剧
定制从查询返回的投影字段
参考样例:
jsdb.inventory.insertMany( [
{ item: "journal", status: "A", size: { h: 14, w: 21, uom: "cm" }, instock: [ { warehouse: "A", qty: 5 } ] },
{ item: "notebook", status: "A", size: { h: 8.5, w: 11, uom: "in" }, instock: [ { warehouse: "C", qty: 5 } ] },
{ item: "paper", status: "D", size: { h: 8.5, w: 11, uom: "in" }, instock: [ { warehouse: "A", qty: 60 } ] },
{ item: "planner", status: "D", size: { h: 22.85, w: 30, uom: "cm" }, instock: [ { warehouse: "A", qty: 40 } ] },
{ item: "postcard", status: "A", size: { h: 10, w: 15.25, uom: "cm" }, instock: [ { warehouse: "B", qty: 15 }, { warehouse: "C", qty: 35 } ] }
]);
-
返回所有字段:不进行任何设置,同基本查询
-
仅返回指定字段和
_id字段:db.inventory.find( { status: "A" }, { item: 1, status: 1 } ),将要返回的字段设置为“1” -
不返回
_id字段:db.inventory.find( { status: "A" }, { item: 1, status: 1, _id: 0 } ),将_id字段设置为“0”With the exception of the
_idfield, you cannot combine inclusion and exclusion statements in projection documents.排除
_id字段后,将不能在投影文档中组合包含和排除语句。 -
返回非排除字段的所有字段:
db.inventory.find( { status: "A" }, { status: 0, instock: 0 } ),将排除字段设为“0”With the exception of the
_idfield, you cannot combine inclusion and exclusion statements in projection documents.排除
_id字段后,将不能在投影文档中组合包含和排除语句。 -
返回嵌入文档中的特定字段:
- 使用
.:db.inventory.find( { status: "A" }, { item: 1, status: 1, "size.uom": 1 } ) - 使用嵌套:
db.inventory.find( { status: "A" }, { item: 1, status: 1, size: { uom: 1 } } ) - 返回结果包括:
_id字段、item字段、status字段、size文档中的uom字段
- 使用
-
排除嵌入文档中的特定字段:同上,将1替换为0
-
数组中的嵌套文档:
db.inventory.find( { status: "A" }, { item: 1, status: 1, "instock.qty": 1 } ),返回结果包括:_id字段、item字段、status字段、instock数组中元素的qty字段 -
返回数组中的特定元素:
对于包含数组的字段,MongoDB提供了以下用于操作数组的投影运算符:
$elemMatch,$slice,和$使用
$slice返回instock数组中的最后一个元素:db.inventory.find( { status: "A" }, { item: 1, status: 1, instock: { $slice: -1 } } )使用
$elemMatch,$slice,和$是唯一的返回数组中特定元素的方法,不能使用索引
查询空字段或缺失字段
MongoDB中的不同查询运算符对空值的处理方式不同
参考样例:
jsdb.inventory.insertMany([
{ _id: 1, item: null },
{ _id: 2 }
])
-
相等过滤器:
db.inventory.find( { item: null } ),{ item: null }查询匹配包含值为null的项字段或不包含项字段的文档 -
类型检查:
db.inventory.find( { item : { $type: 10 } } ),{ item : { $type: 10 } }匹配item字段值为空的文档,例如item字段是BSON类型的Null(类型编号:10),仅返回该字段存在空值的文档 -
存在性检查:
db.inventory.find( { item : { $exists: false } } ),匹配不存在item字段的文档Starting in MongoDB 4.2, users can no longer use the query filter
$type: 0as a synonym for$exists:false.从4.2版本开始,
$type: 0不再是$exists: false的同义词
mongosh 中游标的迭代
db.collection.find()方法返回的是一个游标,为了访问文档,需要遍历游标。在mongosh中,如果没有使用var关键字为返回的游标分配变量,游标将自动迭代20次以打印结果中的前20个文档。
以下示例描了述手动迭代游标以访问文档或使用迭代器索引的方法。
手动迭代游标
将游标分配给变量,游标不会自动迭代:var myCursor = db.users.find( { type: 2 } );
直接调用变量,进行默认迭代:myCursor
使用next()方法进行迭代:
jsvar myCursor = db.users.find( { type: 2 } );
while (myCursor.hasNext()) {
print(tojson(myCursor.next()));
}
可以使用printjson()替换print(tojson()):
jsvar myCursor = db.users.find( { type: 2 } );
while (myCursor.hasNext()) {
printjson(myCursor.next());
}
使用forEach():
jsvar myCursor = db.users.find( { type: 2 } );
myCursor.forEach(printjson);
游标索引
使用toArray()方法遍历游标并以数组形式返回文档
jsvar myCursor = db.inventory.find( { type: 2 } );
var documentArray = myCursor.toArray();
var myDocument = documentArray[3];
toArray()方法将游标返回的所有文档加载到内存中,且会耗尽所有游标。
有些驱动提供对游标的直接索引访问,原理是先调用toArray()方法再使用索引,即var myDocument = myCursor[1]; 等效于myCursor.toArray() [1];
游标行为
-
会话中打开的游标:当相应服务器会话使用
killSessions命令结束时,如果会话超时或客户端已耗尽游标,在客户端会话中创建的游标将关闭 -
会话外部打开的游标:会话中未打开的游标在10分钟不活动后会自动关闭(客户端已耗尽游标时也会关闭),为重写此行为,
mongosh中使用cursor.noCursorTimeout()方法:var myCursor = db.users.find().noCursorTimeout();设置
noCursorTimeout后,必须手动关闭游标:cursor.close()或耗尽游标 -
游标隔离:当光标返回文档时,其他操作可能会与查询交错。
-
游标批次:MongoDB服务器成批返回查询结果。批次中数据的数量不会超过最大BSON文档大小
find(),aggregate(),listIndexes, 和listCollections类型的操作每批最多返回16兆字节,batchSize()可以强制执行较小的限制,但不能强制执行较大的限制find()和aggregate()操作的初始批处理大小默认为101个文档。针对结果游标发出的后续getMore操作没有默认的批处理大小,因此它们仅受16兆的消息大小的限制对于包含没有索引的排序操作的查询,服务器必须在返回任何结果之前将所有文档加载到内存中执行排序
在遍历游标并到达返回批处理的末尾时,如果有更多结果,
cursor.next()将执行getMore操作以检索下一个批处理。要查看迭代游标时批处理中还保留了多少文档,可以使用objsLeftInBatch()方法jsvar myCursor = db.inventory.find(); var myFirstDocument = myCursor.hasNext() ? myCursor.next() : null; myCursor.objsLeftInBatch();
游标信息
db.serverStatus()方法返回一个包含metrics字段的文档,metrics字段包含一个metrics.cursor字段:
- 自上次服务器重新启动以来超时的游标数
- 为防止在一段非活动时间后超时而设置了
DBQuery.Option.noTimeout选项的打开游标的数量 - “已固定”的打开游标的数量
- 打开游标的总数
db.serverStatus().metrics.cursor的返回结果:
json{
"timedOut" : <number>
"open" : {
"noTimeout" : <number>,
"pinned" : <number>,
"total" : <number>
}
}
更新文档
基本使用
参考样例:
jsdb.inventory.insertMany( [
{ item: "canvas", qty: 100, size: { h: 28, w: 35.5, uom: "cm" }, status: "A" },
{ item: "journal", qty: 25, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "mat", qty: 85, size: { h: 27.9, w: 35.5, uom: "cm" }, status: "A" },
{ item: "mousepad", qty: 25, size: { h: 19, w: 22.85, uom: "cm" }, status: "P" },
{ item: "notebook", qty: 50, size: { h: 8.5, w: 11, uom: "in" }, status: "P" },
{ item: "paper", qty: 100, size: { h: 8.5, w: 11, uom: "in" }, status: "D" },
{ item: "planner", qty: 75, size: { h: 22.85, w: 30, uom: "cm" }, status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" },
{ item: "sketchbook", qty: 80, size: { h: 14, w: 21, uom: "cm" }, status: "A" },
{ item: "sketch pad", qty: 95, size: { h: 22.85, w: 30.5, uom: "cm" }, status: "A" }
] );
-
更新单个文档:更新集合中第一个匹配值,
db.collection.updateOne()jsdb.inventory.updateOne( { item: "paper" }, { $set: { "size.uom": "cm", status: "P" }, $currentDate: { lastModified: true } } )$set:更新字段的值$currentDate:将lastModified字段的值更新为当前日期,如果lastModified字段不存在,则$currentDate将创建该字段$unset:删除指定字段,{ $unset: { <field1>: "", ... } },若指定字段不存在,则不会进行任何操作 -
更新多个文档:根据条件判断要更新的文档,
db.inventory.updateMany()jsdb.inventory.updateMany( { "qty": { $lt: 50 } }, { $set: { "size.uom": "in", status: "P" }, $currentDate: { lastModified: true } } ) -
替换:直接替换文档,最多替换一个文档,即使多个文档可能与条件匹配
jsdb.inventory.replaceOne( { item: "paper" }, { item: "paper", instock: [ { warehouse: "A", qty: 60 }, { warehouse: "B", qty: 40 } ] } ) -
行为
- 原子性:MongoDB中的所有写操作都是单个文档级别的原子操作
_id字段:一旦设置不可更改,也不能用具有不同_id字段的文档替换现有文档- 字段顺序:对于写操作,MongoDB保留文档字段的顺序,但:
_id字段永远是第一个字段- 包含字段名称重命名的更新可能会导致文档中字段的重新排序
聚合管道更新aggregate
-
$addFields:向现有文档添加一个字段,输出所有文档,包括已有字段和新字段;重名则覆盖{ $addFields: { <newField>: <expression>, ... } } -
$set:是$addFields的别名 -
$project:将包含请求字段的文档传递到管道的下一阶段。指定的字段可以是输入文档中的现有字段,也可以是新计算的字段$project接受一个文档,该文档可以指定包含字段、删除id字段、添加新字段以及重置现有字段的值,或者可以指定字段的排除 -
$unset:从文档中删除或排除字段,{ $unset: [ "<field1>", "<field2>", ... ] } -
$replaceRoot:将输入文档替换为指定的文档。该操作将替换输入文档中的所有现有字段,包括id字段{ $replaceRoot: { newRoot: <replacementDocument> } } -
$replaceWith:是$replaceRoot的别名
删除文档
- 删除单个文档:
db.collection.deleteOne() - 删除所有匹配的文档:
db.collection.deleteMany() - 通用删除:
db.collection.remove(),用法同db.collection.find() - 清空集合:
db.collection.remove({}),性能较差 - 删除集合:
db.collection.drop() - 删除数据库:
db.dropDatabase()
本文作者:Morales
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 License 许可协议。转载请注明出处!